I’m Canadian, but American politics—and in particular the rise of President Trump—is starting to have a big impact on my life. I look to the south, and I see tribal, ideological, and money-driven politics leading to horrific outcomes. Take illegal immigration.
America today
When illegal immigrants are caught, the government separates families, deporting the parents and putting the kids into adoptive families, all without maintaining records to reunite children with birth parents.
This is the most evil thing I’ve seen a western country do this century—ripping screaming kids from their parents’ arms, getting rid of the parents, keeping the kids, ensuring that families will never be reunited again.
In the last two years, the Republicans have done a lot of evil, but this one resonates with me. It’s physically painful.
The reason this can happen—that the American people are allowing it to happen—is because of tribalism, ideology, and money. It’s reached a point in the USA where not only is nuance gone, but all forms of individual judgment and intellectual honesty. It doesn’t matter what the issue is. If your party supports it, so do you.
I believe at this point the Republicans could be shoveling people in ovens, and still maintain the support of 40% of the population. They’re keeping kids in cages.
My response How the heck is an individual supposed to respond when this is accepted in the free world today? My answer is to look for the polar opposite.
In this case, since the Republicans are right wing, the natural opposite would be socialism. But that’s not where I’ve ended up, because socialism is an ideology just like capitalism. It’s not the capitalism that’s the problem, but rather the blind adherence to capitalism. Blind adherence to socialism would be just as bad.
The real problem is the blind adherence to ideology and party. So to me, the polar opposite is reason.
I want my politics to be about logic and evidence. I’m happy with capitalism in areas where capitalism works well—innovative technology and drugs, the supermarket almost always having affordable food to buy when I want to buy it. I’m also happy with regulation in areas where capitalism clearly doesn’t work—healthcare systems and negative externalities of business like carbon dioxide pollution.
The criteria for deciding what should be capitalist and what should be socialist shouldn’t be driven by ideology or money, but rather by what works. I want my politicians to be grounded in reason, sustainability, ethics, and consensus-building, not blind adherence to right- or left-wing ideology.
My bottom line The only party I see in Canada that crosses that hurdle (which really shouldn’t be that high a hurdle, but somehow seems to be), is the Green Party.
So, in the last municipal election, I volunteered for the Vancouver Green Party, maintaining their technology systems. And on Saturday, I was elected to the Board of Directors of the party. I’m hoping to further improve the Vancouver Green Party’s technology and help ensure that the party doesn’t get tied down in the weeds, but rather continues to focus on evidence-based reasoning.
It’s my response to Trump. If you feel similarly, I’d love to have you join us.
Canada, Mexico, and the USA are in the middle of renegotiating NAFTA, the North American Free Trade Agreement. However, this negotiation has been unlike any other free trade agreement that I’ve seen negotiated because Donald Trump is the president of the US. He’s made negotiating a deal far more difficult than it would be otherwise. His frequent tweets disparaging the Canadian and Mexican negotiators further inflame passions during these negotiations.
I think Trump is extraordinary, and therefore Canadian negotiation tactics must be equally extraordinary, but I think there is fairly clear path forward for Canada.
Trump is Special
So much of these negotiations are dictated by Trump’s personality. Trump is surprisingly ignorant for the leader of a country, but covers for his ignorance by disregarding facts and asserting whatever he wants. Then, he defends those fantasies vociferously. Because he doesn’t seem to care about ethics, he’s not ashamed of this strategy, but instead is proud of it, to the extent that he has bragged about it to Republican donors.
What’s more, Trump is fine with not standing by the deals he does make. He has a long history of stiffing banks and contractors. On top of that, he’s capricious. Even if he concedes a particular position on one day in exchange for concessions from Canada, it’s not clear that he won’t change his mind about that concession the next day. And, I don’t think he’d care at all about anything that his trade negotiators agree to, keeping or discarding their deals as suits his needs.
Finally, Trump seems to be a narcissist—he seems to care a lot about having the camera on him, and reacts in extreme ways to negative press.
The strategy
Of course, these personality traits make negotiation with Donald Trump difficult. There’s the risk that anything your side concedes is considered final, and anything Trump concedes is considered temporary, able to be withdrawn in an instant. But, these personality traits also provide a huge advantage to anyone negotiating with Trump, and that is the complete freedom to negotiate unethically.
Typically, in negotiations, each side should negotiate in good faith, being willing to give and take, and expect the other side to give and take. In the end, through good faith negotiation, you’d expect the things each side cares the most about to be “won” by the side that cares the most about them, with the less important items to be sacrificed to win the key deals. And, one would also also expect the person you’re negotiating with in good faith to actually want to make a deal.
But, since these negotiations aren’t in good faith, Canada can ignore that. Thus, I believe that the optimal strategy is to do everything possible to extend the negotiations. NAFTA remains in place while negotiations continue and, to all appearances, USA doesn’t want to cancel without a new deal in place. So there’s no need for Canada to rush and no reason to believe that a reasonable deal is possible with Donald Trump at all.
Thus, Canada should simply run out the clock. We should negotiate in bad faith, sticking on every point, flipping back and forth on potential concessions, and taking frequent adjournments to consider the American arguments. We should frequently compliment Donald Trump about his negotiating savvy, feeding his narcissism so that he doesn’t get impatient, waiting for time to tick away on the Donald Trump presidency. When the next person is in place, both sides can go back to negotiating in good faith.
The backup strategy
Blinded by spotlight shining on him, it’s unlikely that Trump will figure out this strategy. But if someone tells him, there’s a small chance Trump may get more aggressive in negotiations, or even back out of NAFTA.
Under such a scenario, Canada does have a reasonable counter-punch, and that’s backtracking on our recognition of American intellectual property laws. America cares a lot about IP—more than any other country in the world—and that’s because a huge part of America’s economy is based on IP. If Canada stuck back there, it could have severe consequences in the USA.
Before the USA-Canada Free Trade Agreement, Canada’s IP laws were far less strict, and we can return to those days. Canada could, for the health of its citizens, declare American drug patents invalid in Canada. Then, we could set up our own drug manufacturing facilities for producing and exporting medicine worldwide. USA controls about 45% of the global pharmaceutical market, and Canada creating generic versions of American on-patent drugs would be a huge economic slap in the face.
If you extend that strategy beyond pharmaceuticals to content and brands (Canada’s own Mickey Mouse!), the impact on the American economy could be huge.
The bottom line
I don’t think the backup strategy should be the primary strategy because I don’t think it’s wise to escalate trade tensions when they’re already so high. Heck, Trump is an authoritarian who seems to really want to subjugate people, and more fascist than not.
So if Canada did go after American IP, there’s a small chance that Trump’s response would be to invade Canada (remember, this is the guy who didn’t understand why using nuclear weapons was a bad idea). Thus, I think a passive aggressive strategy of wasting negotiating time is more likely to result in a positive outcome and less risky than a more aggressive negotiating strategy.
Artificial intelligence—and neural nets in particular—have been gaining attention lately. The most prominent example is the rise of self-driving cars, but the example that made me sit up and pay attention was the news that a neural net created by Google called AlphaGo had defeated one of the top go players. For me, this was a particularly noteworthy event.
Kasparov, the best human chess player of the 20th century, lost to a computer in 1997. That defeat surprised some, but I was studying computer science from 1990-1996, and it was generally accepted by most computer scientists at the time that within years computers would be better at humans at chess. So that defeat was relatively predictable.
But in the mid-1990s, the general consensus seemed to be that it would take a lot longer for a computer to master go—I remember wild guesses that it would take until 2050 or even 2100 before a computer challenged humans in that game. So, when AlphaGo won, it meant that something big had changed in the world.
And I wanted to find out what it was. In university, I did some of computational linguistics (teaching computers to understand human languages), but nothing related to neural nets. So, I decided to take Andrew Ng’s deep learning courses on Coursera to find out what I’d been missing. I found a couple things that surprised me.
How neural nets work
The first thing that surprised me (and this might indicate just how ignorant I was about the topic), was the realization that neural nets are just big math equations.
To train a neural network, you’re saying, “If I think a math equation has a particular form, what constants will make that math equation true most of the time.” Similarly, when you do predictions with the neural network, you’re just taking an input and running it through the math equation to see what the answer is.
So, the go-playing computer is essentially a big math equation that takes as input the location of each stone on the board, and spits out location where the next stone should be placed.
Why do I find this surprising?
The reason I found that surprising is because the process of training the network is basically nonlinear regression. “Nonlinear regression” sounds scary, but, if you take away the intimidating terminology, it’s a concept that most people understand intuitively.
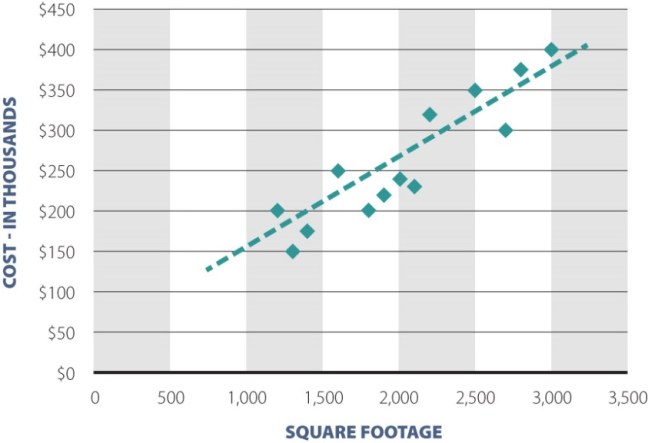
If you look at house prices, you’ll find that houses with more square footage generally have higher price. So take a bunch of houses, and for each house, put point on the chart, like the picture above. The more square footage, the farther to the right the point. The more expensive the house, the higher up the page. You’ll end up with a bunch of points that roughly form an angled line. If you draw a line through those points as in the picture, you’re doing linear regression.
Nonlinear regression is the same thing, but instead of drawing a line, you’re drawing a smooth curve approximating those points. (Nonlinear = not a line.)
Building a neural net is like staring at a bunch of points, deciding a particular type of smooth curve will go through most of those points, and then figuring out what the curve should be.
The challenging bit
Of course, when you’re telling a computer to draw the curve, it becomes a bit more complicated because you have to tell the computer exactly how to decide which curve is best. But even then, the concepts aren’t particularly complicated.
One common way to decide which curve is best is to find the curve that minimizes the distance between the curve and all the points-we want each point to be as close to the curve as possible.
But, if you have, say 10,000 points, calculating that exact curve can be hard. So hard that the people designing neural networks don’t even bother trying to solve the problem. Instead, they guess what a solution might be, see how badly their curve fits the points, and then make another guess until they get an answer that’s close enough to make people happy.
An example
For instance, suppose we decide a line will fit our points well, and we’re just trying to figure out the slope of that line. Furthermore, suppose that (though the neural net designer doesn’t know this), if you try different values for the slope, calculating the average distance of each of those points from the line, you find that the curve looks like a parabola (the blue parabola in the picture below). Essentially, if we guess the slope of the line is 2, we calculate that the average point is a distance of 4 away from the line. When we guess 1, the average point is a distance of 1 away.
A blue parabola with a red tangent line at 2, 4
Since we want to minimize the average distance of the points, we want to find the lowest point in the parabola. If you look at the picture, this place is clearly the zero position—that’s the lowest part of the blue curve.
But the neural net scientist doesn’t know that the relationship between slope and distance is a parabola, so they might randomly guess that the minimum point is at the 2 position on the axis. They’ll run the numbers, and see that the curve at that point is still sloping down, so the actual minimum must be to the left of 2.
So they need to guess again with a number that’s less than 2. To pick that new number, they’ll draw the red line showing the slope of the curve at position 2 and see that it intersects the horizontal axis at 1. So then they’ll guess that 1 is the answer.
But even at 1, the curve is sloping, so they’ll have to repeat the process, drawing the red line again, coming up with a new guess, this time coming up with 0.5. And they’ll keep repeating the process, walking ever closer to the actual minimum at zero, finally quitting when they decide they’re close enough.
Thus, they might eventually conclude that the slope of the line should be 0.0001 and in this way. they will have found the curve that (almost) minimizes the distance between the pints and the line.
Adding complexity
So, if this is all neural nets are—equations that are derived from minimizing the distance of a bunch of points from a curve—the obvious question is, “why did it take so long to get to where we are?” The answer is that, while my examples are in two dimensions, the neural net that actually work are solving equations in much higher number of dimensions. Instead of trying to find the bottom of the parabola, imagine trying to find the bottom of a bowl. Doing this changes the two dimensional parabola problem into a three dimensional bowl problem.
And neural nets don’t stop there, but usually have a much higher number of dimensions. I imagine most “real” neural networks today have at least a thousand dimensions they are trying to solve for, making the resulting equations far more complex. For instance, if you want to analyze a 640×480 photo (with three color dimensions) to decide if it contains a stop sign, you need an equation that has 921,600 inputs. Then, you have to find the thousands of parameters that take those inputs and spit out a simple “yes” or “no” when asked if there is a stop sign in the picture
So, these equations are really big and complex, and historically we didn’t have the processing power work out the equations in reasonable amounts of time. Neverthless, I find it remarkable that, despite this complexity, the core ideas used to create neural networks are rather intuitive. We take something simple and understandable and get something remarkable when we multiply it ten-thousandfold.
The second surprising thing
The other thing that surprised me about neural networks was related to the course itself. In Ng’s course, the majority of the citations were between 2010 and 2016. While neural networks were certainly a thing when I went to university in the early 1990s, the technology has progressed so rapidly in recent times that most of the citations in a “start from nothing and learn neural networks” online course are from the last 8 years. Forget the self-driving cars, the game-playing robots, and the media buzz. To me, those citations are indicative of just how much neural networks are exploding right now.
The first time I heard the word “incel” was immediately after the van attack in Toronto. But since then, I’ve spent a fair amount of time trying to understand that movement because I was intrigued that I was so far out of the loop on a largely online pop culture development. My hypothesis now is that the incels, not the Muslims or radical right, are likely to become the most frequent domestic terrorists within North America.
What are incels?
Incel is a contraction of “involuntary celibate”. While the label initially was intended to be ironic and gender neutral, it quickly evolved to represent a group of men who want to be in a romantic relationship but aren’t. While some in the group seem simply cynical and withdrawn, the broader group seems furious.
People have characterized the incels as misogynistic, but I find it curious that this label seems to be sticking simply because it notably understates the situation. From what I’ve read, many incels certainly have the “I’m entitled to rape” attitude, but also seem to fervently hate males who are getting sex, railing against the “Chads”. Elliot Rodger—as far as I know the first incel mass murderer—killed four men and two women. Incels aren’t just blaming women—they’re blaming everyone for their situation except themselves. So, I think these guys are misanthropists, not just misogynists.
Why incels can be dangerous
The reason that I view the incels as particularly dangerous is because they are disconnected from society. Muslims are connected within their community and pretty well every Imam in North America delivers a message of peace.
In contrast, with the incels, we’re dealing with lonely people with poor social skills who have literally lost hope of having romantic relationships. While the incel movement puts the emphasis on sex, to me, that’s actually missing the key point. Romantic relationships aren’t largely about sex. They’re about being valued as a person. I think that’s why incels blame everyone else for their situation—because incels have become disconnected from the community that doesn’t seem to value them.
That’s why these guys are a terrorist threat. If someone is without hope and feeling persecuted by society, I think it’s quite easy for them to become radicalized. After all, what do they have to lose?
The natural solution
From what I read after the Toronto attack, most people seemed to believe that we should fight back against the incel movement using social pressure. “We should ostracize the incels, making it really clear that incel attitudes are completely unacceptable” was by far the most frequent argument. In fact, initially, this was my angry response to the attacks, too.
I’ve since reconsidered. While extracting social revenge on incels would be emotionally satisfying, it’s unlikely to have a positive effect, but rather worsen the situation.
Incels are feeling disconnected from society, as if the world is deliberately designed to persecute them. Ostracizing incels would be further detach them from society, and provide strong evidence they’re actually correct—that society is persecuting them. It would validate their worldview.
What’s more, I don’t think we need to make it clear to incels that society considers rape unacceptable—that’s completely obvious. For my entire lifetime, the discussion hasn’t been whether rape is acceptable, but rather about what actions constitute rape.
Someone could argue that incels are horrible, so it’s irrelevant if ostracizing incels makes them feel like garbage, because they are. But, even if you put aside the counter argument that it’s evil to deliberately exclude people and make them feel worthless, I think that’s a short-sighted view.
As technology progresses, it becomes easier and easier for a single person to kill a large number of people. Feeling superior and righteous kind of works when only ten people are killed and you don’t actually know any of them. But when the technology exists that enables some disgruntled scientist to kill millions using something he created in his garage, then one should really move beyond righteous fury to actually finding solutions. There’s real value in reducing the chance of an apocalypse.
The hard solution
So, I think the solution has to focus on some sort of outreach—identifying incels and individuals likely to become incels, and reattaching them to society. In essence, the strategy has to revolve around coming at incels from a place of love rather than hate. This doesn’t mean accepting incels’ misanthropy, but rather connecting with them as people who have value even if they aren’t in a romantic relationship. I believe that, once incels are reattached to society, all these negative and destructive attitudes that incels embrace will melt away.
Now, this might seem like the ravings of a feverish hippy, but there is evidence to support this approach. Dealing with racism seems harder than dealing with incels because skin color is such a visible barrier. Yet, this strategy has helped white supremacists back away from their ideology. What’s more, if you examine the scientific basis for torture, you find that “interrogators reported that rapport and relationship-building techniques were the most effective regardless of the interrogation goal. Confrontation techniques were the least effective.”
Thus, if a relationship-building strategy works to disarm hate groups and extract information from hostiles, it seems like a sensible approach to try with incels as well.
The likely outcome
That said, while I think the approach I propose has the highest chance of success, I think it’s hard to implement. Even if one agrees that this strategy is likely to be the most effective way to eliminate the incel threat, it’s difficult to convert this broad philosophy into actions.
What’s more, I think North Americans in general don’t care much about what works—they care mostly about delivering their righteous revenge. So, I think the ostracization and condemnation strategy is far more likely to be the North American response. Consequently, I think we’ll see incel-linked violence growing in both frequency and degree.
This book gives me considerable satisfaction in that it ties together several of the threads and mysteries that have spanned multiple novels. I tend to be an ideas guy—reveling in how simple concepts can grow and mutate into monsters that look nothing like the original idea.
Well, very early on, while I was outlining my first novel in my head as I walked home, an idea came to me that literally made me gasp. It was a barbaric and horrifying idea, one that really needed to be shared.
The challenge was, it needed a long runway. To give context to the idea, I needed to create the universe of the book and give the idea time to simmer, to grow into its full, magnificent awfulness. It’s perhaps not much of an exaggeration to say that I wrote three books in order to get this idea onto the page.
And now, with The Battlefield Uprising, I’ve done that. I hope you like it.
Last summer, Ontario started a three year test study of the impact of a minimum basic income of about $17,000 for individuals and $24,000 for couples. The core idea of this policy is that every citizen receives that a basic income paid for by the government. Any income they make on top of that income, (from, say, working), is taxed, but doesn’t reduce their basic income.
Interestingly, a parliamentary budget officer has calculated the annual costs of implementing a similar program nationally.
What’s the appeal of the basic income?
The basic income has several nice features. First, it’s easy to manage. Because every adult gets it, there’s little bureaucracy required to manage it. This is very different than, say, welfare or employment insurance, where constant paperwork is required to ensure that recipients are meeting the requirements of the programs. In contrast, you can implement a basic income simply by gluing it on to the existing tax system as as a negative tax.
Second, unlike many government programs like subsidized housing, the basic income allows recipients to spend money in the way that provides the most value to them. While Jack might want to spend 40% of his budget on housing, Jill might only want to spend 30% and use the extra 10% for better food. A minimum basic income allows the flexibility for them to both get what they want. Milton Friedman, the Nobel Prize-winning free market economist supported the idea of a basic income because of this feature and the low cost to the government of administering such a system.
Third, welfare and unemployment insurance programs can make working non-economic for some people. When an unemployed person gets a job, they lose their welfare payments and employment insurance benefits. So, some unemployed people can be in the position where working at a 40-hour a week job only provides an extra couple of hundred dollars a month in income over welfare, and that money is eaten up by job-related costs like transportation and childcare. With a minimum basic income, in contrast, every extra dollar earned will be income on top of the basic income.
Fourth, the minimum basic income helps to alleviate the genetic lottery effect. Children born of poor parents have worse outcomes than children born of wealthier parents. Thus, ensuring that poor parents have at least the basic income will likely result in better outcomes for their children.
One of the basic income studies showed that the only two groups of people who were less inclined to work when provided with the basic income were a) young adults—who were more likely to go to school—and b) parents—who were more likely to choose to stay home with their children. If poor parents are able to spend more time parenting and their children become less constrained by economic factors when deciding whether to pursue an education, it’s likely to improve income mobility, reducing variance resulting from the genetic lottery.
The costs
These aren’t the only benefits of the minimum basic income, but are just some of the biggest, most well-established benefits, and the second-order effects could be as significant as the primary benefits. But, it’s easy to say that everyone should own a beautiful house and an expensive car—we also need to look at the costs.
In Canada, the expected cost of a program similar to the one in Ontario would be $76 billion per year. But, since creating such a program would eliminate other programs for low-income Canadians like welfare, another $32.9 billion would be saved, leaving the net cost at $43.1 billion.
It’s unclear from the reporting on this story whether employment insurance has been taken into account when calculating this number, but if not, there is the potential for more savings there. While not all of the $21 billion in employment insurance expense could be diverted, perhaps some of it could. Something similar might be true for the $51 billion spent on old age security.
In any case, $43.1 billion is a large number, but not out of reach. The total projected federal expenses are around $330 billion, so the cost would be about 13% of the total budget. Interest on the national debt is about $24 billion—if Canada hadn’t overspent in the past, we’d be over halfway to having enough money to implement such a program.
The $43.1 billion number also compares nicely to the size of our economy. It’s about 2.2% of Canada’s $1.96 trillion GDP. And it’s less than 18% of Canada’s $242 billion in healthcare expenditures (and there’s a reasonable chance that a minimum basic income would reduce healthcare expenditures). So, the program wouldn’t actually be that big compared to the size of the economy or other far-reaching government programs.
So, financially, it seems to me that if Canada wanted a minimum basic income, we could figure out a way to afford it.
Second-order effects
That said, I don’t think it’s a completely obvious program to implement, simply because the second order effects scare me. I think it’s likely a good program, but nobody’s actually implemented such a program before and seen the long-term impact, so there could be some unforeseen catastrophic consequences.
For instance, suppose that a basic income program results in all low-income employees quitting, requiring salaries to double leading to high inflation that negates all the benefits of the basic income and then some. I don’t think such a scenario will happen, but it isn’t completely out of the realm of reason. Thus, because such a policy could potentially have a huge negative impact, it makes sense to move slowly, continue to do studies, and see how other implementations fare.
Nevertheless, with the rise of automation, I believe some form of basic income is required. With every other innovation, human labor has been displaced, but after a generation, has moved into other industries. Automation has the potential to be different, literally making human labor unnecessary.
While it’s pretty foolish to suggest that the entire economic system might change to make human labor obsolete (particularly in light of centuries of similar fears that never came to pass), I don’t see how this doesn’t happen. Suppose a robot is invented with all the capabilities of a human that is also able to build an identical robot using nothing but solar energy and carbon dioxide from the air. There would be no need for human labor.
My bottom line
A minimum basic income is the only solution I’ve heard that will solve this excess human labor conundrum in an ethical and stable way. So, I think there’s value in continuing to investigate and adopt this solution. Then, as humans are displaced by automation over the next century, the program can be expanded to ensure that the great mass of humanity isn’t left behind, but rather shares the benefits of innovation in the post-labor world.
Bill Gates recently recommended the book Factfulness by Hans Rosling, a man who, about a year ago, changed my perspective about the future of the world. I’m not exactly a devout Malthusian, but I thought some aspects of Malthus’ arguments are compelling. If the earth’s population grows exponentially—as it has in the past century—and the earth’s resources are limited—which is obviously true—then at some point, one should expect a reckoning as the earth’s population exceeds the capacity of the earth to support it.
Rosling disabused me of that notion with this excellent video. While there are many things to worry about, I now believe that overpopulation isn’t one of them.
The historical problem
Historically, families would on average have six kids. Exponential growth is tricky to understand, but even basic back of the napkin calculations make it clear that there is a big problem with this birth rate.
The world’s population in 1AD was estimated to be about 300 Million. If you assume on average, children are born when the mother is twenty-five years old, then that means between that time and 2000 AD, there were about 80 generations. If each pair increases the population by approximately three times (a man and a woman making six children), then the 300M population quickly becomes extremely large—roughly a trillion multiplied by a trillion multiplied by a trillion multiplied by a trillion multiplied by ten trillion.
Of course, the population on earth is nowhere near that 10 to the power of forty-six number. In fact, the earth’s population grew extremely slowly, only reaching a billion by the early 1800s and two billion by 1925. The reason for the discrepancy is that many kids—the majority in fact—died without reproducing. Only slightly more than two of those six kids would actually have their own children. As a result, population growth was slow.
Hitting the wall
The problem arose, of course, when those kids started surviving. In Canada, as a result of improvements in healthcare and safety, only about 1% of people die before the age of 25. And, while fewer children dying is a good thing, if everyone’s having six kids and they’re all surviving, the exponential growth quickly creates problems.
But those problems didn’t actually arise because people in Canada are having fewer kids. In Canada, the average woman has about 1.6 kids, well below the rate of repopulation. The only reason the country’s population is growing at all is because of immigration.
But the world’s population is still growing. When I was in grade school, the population topped 4 billion, and today it’s almost double that. So, even if Canadians aren’t having a lot of kids, other people are. Therefore, overpopulation is still a threat, right?
Nope
Rosling’s answer is a definitive “No!” While the earth’s population is still growing, Rosling looks at the relationship between development, wealth, and the number of births and makes the argument that as people get wealthier—and more children survive—people have fewer children. In fact, most developed countries are at or below the repopulation rate, and pretty well every country has a falling birth rate.
As poorer countries become wealthier and gain access to better healthcare, their birth rates will continue to fall, approaching those of developing countries. In fact, Hans Rosling argues that right now, we have hit the level of “peak children”, that we’re in a situation where birth rates have fallen to the extent that the number of children alive today is likely to be greater than or equal to the number of children alive any time in in the next hundred years.
In other words, right now, birth rates are at a repopulation level, but no higher.
The earth’s population will continue to increase for a while because, even with births exactly equal to the replacement rate, it takes a couple of generations before flattening birth rate makes it through the higher age groups. Suppose the 50-year-old cohort today came from 50 million births fifty years ago. If for the next 100 years we have 100 million births per year, then in 50 years, the 50-year-old cohort will be from a group of 100 million births and will therefore be larger than the 50-year-old cohort today. Thus, even if births are identical for 100 years, we will still have the population grow until the smaller generations are replaced by the bigger generation.
Some interesting consequences
In a way, the flattening of the world’s population growth makes sense. If parents were having six children because they expected four to die, then intuitively, you’d expect them to only have two kids if they expect all their children to survive. But the fact that this hypothesis appears to be true in practice is nevertheless reassuring.
In fact, it’s great news, because it means that one major risk, that the world would become an overpopulated Fifth Element wasteland with billions fighting for scare resources, will not come to pass. That’s one less thing to worry about.
This outcome does have its own problems, of course. Our society is built on the assumption that population growth will increase indefinitely. Social programs like pensions are designed to have the numerous young people provide an income to the few older people. If the young don’t outnumber the old, then the math behind our pensions breaks, and they have to be redesigned. A similar problem exists with government spending. Government debt is far less onerous if you know that simple population growth will lead to GDP growth that can be harvested to pay interest on that debt.
So, society and governments will have to figure out ways to address this major change. In Canada, the government’s approach seems to be largely about not tackling the issue head-on, but rather importing a bunch of immigrants and temporary foreign workers to keep the old models working for as long as possible. Even so, it seems likely that, in my lifetime, we will need to create sustainable new models that work in a world where population growth is zero.
I’ve recently been watching Parenthood, a TV drama revolving around the three generations of the fictional Braverman Family, like a less intense version of This Is Us. One thing that’s striking about the show is how often a major plot revolves around the parents lying to the children. When confronted with difficult questions from their children, the first instinct of the parents seems to be to lie.
I find this strategy very strange. It makes me wonder whether this is truly how most parents deal with difficult questions, or whether it’s just a method the writers are using to jump start the narrative.
Why we don’t lie
Largely, my wife and I don’t lie to our kids, and certainly not about anything important. We do this for several reasons.
First, I want my kids to be able to speak to me about important things, and trust that I’ll tell them what I see as the truth. Kids are almost completely dependent on their parents for knowledge, and need to know that, within my limitations, I will share the truth with them. I need to be trustworthy, reliable source of information. After all, if I am going to lie to them when they’re four about where babies come from, why the heck should they believe anything I tell them about drugs when they’re fourteen? If I lie, I’m saying, “Don’t bother coming to me for information. Go to your friends instead.”
Second, a large part of human interactions is based on attachment—being loved, trusted, believed and valued. As a parent, the biggest part of my job is forming a healthy, two-way attachment with my child. Lying to them breaks the bridges of attachment.
Third, lying about important things is simply wrong, giving children a skewed perspective on the world. I expect my children to learn to make their own decision in the world and to be able to weight facts and opinions in making their decisions. But how can they do that if their own parents, the people they’re supposed to be able trust, aren’t actually giving them accurate information?
Fourth, if I lie to my child, it’s essentially saying that lying is acceptable in our relationship. Thus, through my actions I’m indicating that it’s reasonable for my child to lie to me.
Finally, I find it loathsome when parents lie to children simply because the topic is uncomfortable. I’m the adult in the relationship. I should be able to put aside my discomfort in order to do what’s best for my child. Some conversations are difficult, but that’s what I signed up for when I made a kid. My child shouldn’t be held responsible for helping me manage my emotions; I’m responsible for helping to manage theirs.
The fine print
Of course, it’s also true that kids might not be ready for in-depth conversations at a young age. I’m not going to tell a 5-year-old the details of how a Jewish child would be killed by Zyklon B in the Nazi death camps. But if my kid asks what the Nazi’s did wrong, I’ll tell them that they started a war that killed millions, and murdered millions of their own people.
To me, the fact that the child is asking usually means that they’re ready for some sort of answer. The answer I’d give primary school student probably wouldn’t have the same detail as an answer as I’d give a high school student, but that’s true of pretty well every communication, comfortable or not. In both cases, though, my answers would be honest.
I suppose if pushed, there might be some questions I wouldn’t want to answer because I think the answer would be harmful to the child. I’ve never encountered such a question in the wild, but I can imagine some really specific questions that I wouldn’t want to answer. In such as case, I still think I wouldn’t lie to my child, but rather tell them honestly that I was reluctant to answer the question because the answer might give them nightmares.
The Santa question
Of course, in our house, this “don’t lie about the important stuff” also applies to Santa. To an adult, it might seem that lying to a child about Santa is a harmless game, but to a child, Santa certainly falls into the “important stuff” category. To me as a kid, Christmas was the most amazing thing ever, like no other holiday. To lie about the core concept of Christmas seems like a huge betrayal.
A counterargument might be that Santa helps to provide the magic in Christmas, but I don’t really think children need any help with that. The holiday is magical enough without needing to lie about the existence of fictional characters.
In fact, when I was a kid—in fact probably up until I was about twenty-five—the whole world was a source of wonder. Everything were new and breathtaking. I remember being so excited learning that computers had different fonts. In my first week of university, I was delighted to discover I could go swimming for free in the university pool—every day if I wanted to! I remember my awe at seeing a deer on the side of the road, frozen like a statue for ten seconds before it hopped off into the forest.
Watching sunsets, meeting friends, climbing trees, visiting karaoke boxes, walking around downtown, eating a new flavor of ice cream, discovering tiny hairs on my first girlfriend’s stomach, reading about a really neat idea…. When I was young, almost every day, I’d experience something new and exciting.
The world was wondrous and magical. There was no need to add a Santa lie to increase the magic.
My bottom line
Thus, I think it’s generally a bad idea to lie to children. What’s more, I think parents can have just as much fun playing pretend games without lying to children, convincing them that the make-believe is real. I just wish these TV shows would model how a trusting relationship between a parent and kid can be built without the parent lying to their child.
In my previous blog, I discussed my ambivalent feelings about the #metoo movement, and now it appears that the world is conspiring to throw another perplexing tangle into my brain, the issue of implementing discriminatory policies for the social good.
This issue has come up a lot for me recently. It started with the proposed Bill C-25, specifically PART XIV.1 172.1, Disclosure Relating to Diversity. This law proposes that businesses be required on an annual basis to disclose diversity-related personal information about directors and senior managers. It continued with Canada’s recent Gender Equity budget, focused to a huge degree on identity politics. And then this week, Google has faced lawsuits for implementing systemic discrimination against white and Asian applicants in their hiring processes.
When an issue hits again and again, it gets my thoughts churning.
My biases
I really struggle with this issue because there’s certainly been historically bias against minorities and women in most aspects of western culture. I also think that discrimination exists today, though clearly not as much in the past. What I’m confused about is the degree to which discrimination exists today and the right way to tackle the issue.
The issue is complicated by the fact that I’m a white male. Thus, I have an emotional reaction to policies that will discriminate against whites and males, likely very similar to the emotional reaction a black woman might have against policies that discriminate against blacks and females. Thus, it’s hard for me to separate the logic of my analysis from my emotional knee jerk reactions.
I also believe that there’s something to be said for the expression, “When you’re accustomed to privilege, equality feels like oppression.” It’s a brilliant saying because it really gets to the emotional heart of the challenge of righting disparity. At the same time, I find it dangerous, because it can be misused to dismiss real concerns. Oppression also feels like oppression.
So, that’s why this topic is challenging to me—it’s hard to define the problem, it’s hard to separate reasoning from emotion, and it’s hard to find solutions. Of course, that’s also why it’s an interesting topic to discuss.
Over the line
To me, Bill-C25 is a huge problem, because I believe it is wrong for corporations to be collecting information about their employees’ gender, ethnicity, and sexuality, and even more wrong for them to publish it. People should have the right to control the disclosure of their own personal information. It shocks me that people who in the last century saw attempted genocides in Germany, Bosnia, Cambodia, Rwanda, Burundi, and Iraq think it’s a good idea to create huge public databases that identify people by ethnicity, highlighting the most successful members of each ethnic group.
The Liberals don’t want these databases so that they can persecute minorities, but it seems clear to me that in this world, weird stuff happens. Donald Trump got elected in the USA. Who’s to say that something equally strange couldn’t happen in Canada? And if it does, I think it’s a bad idea to have a ready-made list of leaders in ethnic communities that a racist Prime Minister might want to persecute.
To stop political horrors from happening, you want it to be difficult for governments to do horrible things. You want people to be able to hide, to fight back. So, there’s value in not creating governmental infrastructure to make persecution easy.
Discrimination for good
The more challenging issue for me is deliberately implementing discriminatory systems to put white males at a disadvantage relative to other people. I have so many different perspectives on this one.
First, if women or ethnic groups are at a disadvantage as a result of their gender or ethnicity, that’s a big problem for me, and a problem that should be addressed. However, the evidence of that discrimination doesn’t seem particularly solid. For instance, there was an Australian study showed that gender and ethnic-identification information was stripped from resumes, males were actually more likely to be short-listed for jobs. Similar blind-hiring results have been found in Canada as well, supporting the surprising idea that hiring practices discriminate against men.
The gender pay gap data is also difficult to interpret, partly because the numbers are very political and because it seems like it’s almost impossible to get an apples to apples comparison. I think there’s a pay gap, but I’d be hard pressed to find evidence that actually proves it conclusively.
My second thought is that implementing systemic discrimination against another gender or ethnic group seems like a terrible solution. Because then you’ve implement systematic discrimination against a group based on their gender or ethnicity.
It’s not that the proposed cure would be worse than the disease, but rather than the proposed cure is the disease. If I abhor the idea of people of one gender being discriminated against, I’m not sure why I shouldn’t also abhor the idea of people of another gender being discriminated against.
Intellectual honesty
The other big problem with this effort to improve equality though discrimination is that it doesn’t seem to be intellectually honest because governments appear to be focused only on correcting injustices that affect women and minorities, not others.
For instance, more women than men have been going to university, to the extent that in Canada in 2009, 34% of women aged 25 to 34 had a bachelors’ degree, while only 26% of men did—a 31% difference. Since then, the ratios have become even more skewed. Yet there hasn’t been a high-profile push to get more men into university, or determine why Canada’s education system is failing males.
Similarly, one often hears about how the gender gap in science and engineering needs to be addressed, but it’s very rare that one hears about how problematic it is that there are so few men in nursing. In the US, fewer than 10% of nurses are male, and I imagine the statistics aren’t that different in Canada. I’m not sure why it’s more important that women work in construction jobs than men work in nursing jobs, but based on the latest federal budget, the Liberals seem to believe this is the case.
The injustice of the justice system is even more of a concern. Men face significantly higher conviction rates than women. What’s more, a recent American study shows that men on average face 63% longer prison terms than women (from memory, a Canadian study discovered a similar difference). While people are (rightly) outraged about the statistics when it comes to the conviction rates and sentences for aboriginals, they largely don’t seem to care about bias against men.
Now, I don’t know if other factors explain these discrepancy—men are generally bigger and stronger than women, so one could expect them on average to do more harm than a women when committing, for instance, assault. The greater damage they cause might factor into sentences. But even so, such big unexplained differences in conviction rates and sentences is worrisome.
My bottom line
To be clear, my argument isn’t that the government shouldn’t attempt to correct injustices. Rather, some governments’ tendencies to focus on particular injustices and ignoring others makes me wonder whether the goal of such governments is to actually reduce inequality, or to pander to their base. And that makes me even more skeptical of policies that attempt to reduce discrimination by implementing systemic discrimination.
Today in Canada, female government employees outnumber male employees by about 70%. More than just about any other employment statistic, that particular ratio is under the government’s control. Thus, if the government is sincere in its belief that diversity is good, gender inequalities need to be addressed, and discriminatory policies are the best way to address them, then I would expect them to implement policies to discriminate against women in government hiring until this inequality is corrected. But I suspect they won’t, which makes me cynical when they suggest this approach in other areas.
Thus, while I’m concerned gender and ethnic inequalities, I’ll remain nervous about policies that attempt to solve the problem by judging people not by the content of their character, but rather the color of their skin. And remain frustrated while I continue to seek just ways to address discrimination.
I think the #MeToo movement is a net positive—I think it’s good that women are feeling more comfortable about speaking out about sexual assaults by people in positions of power. I want people to feel like they can talk about abuse, and that when they do, to know that they will be taken seriously, with consequences to the abusers.
But at the same time, I’m wary of witch hunts. The challenge is that an allegation seems like it’s enough to destroy careers, and it seems to be difficult to find a balance between justice and mob rule. Thus, I’m confused about how, over the long term, #MeToo should all shake out.
Guilty because accused
I’d say that it’s almost certainly true that, overall, the media and the people are on the side of women who speak out on this topic, so I won’t speak too much about that except to say that we should take all allegations of sexual assaults seriously.
But the more interesting side to look at now is whether it’s fair and reasonable that mere allegations should ruin people’s careers? Margaret Atwood penned a good essay on this subject talking about how problematic a “guilty because accused” attitude is.
I think Atwood raises valid points, to the extent that I’m uncomfortable with Justin Trudeau’s argument that it is “essential” that women be believed when they raise allegations. To me, that seems dangerously close to the “guilty because accused” line.
The other side
To me, it’s reasonable to say that most women who accuse people of sexual assault are truthfully expressing their view of the situation. But there are two big problems with taking that stance and continuing on to the natural conclusion of “therefore the accused is guilty”.
First, perspectives of the same event can be different, and there’s no reason why one individual’s perspective should be given more weight than another. Being uncomfortable with a sexual advance doesn’t imply that the sexual advance was necessarily inappropriate in any way.
A large percentage of romance movies have an attractive man persistently stalk and harass a woman until she falls in love with him, while many thrillers have an ugly man stalk and harass a woman until she’s eventually forced to kill him. The main difference between these two types of movies seems to be the lighting, the music, and the attractiveness of the man (i.e. differing perspectives). One could argue that in both situations the man is in the wrong, but society don’t actually seem to believe this because it comes up again and again in the most beloved romances.
The second issue is false accusations. I think the vast majority of accusations are true (and, in particular, accurately portray the woman’s perspective), but I don’t believe that all accusations are true. And ruining someone’s career over a false accusation is really bad. I don’t think it’s reasonable toss the falsely accused in a “collateral damage” bucket to be ignored simply because most accusations are true. To do so would be akin to saying school children being murdered every few days by the rare psycho is acceptable collateral damage in return for gun rights.
More than an academic argument
And I think that this argument is more than just a theoretical argument. I certainly have a very negative impression of Jian Ghomeshi, and he lost his career and several years of his life to sexual harassment charges, yet he was acquitted of all charges. What it just that he lost his career? I’m not sure.
Patrick Brown is even more extreme. Within five hours of sexual assault allegations, he was made to resign as leader of the Ontario Conservative Party. Yet the worst accusation—that he was propositioning a minor—has turned out to be false. The less serious accusation was that he invited an intern to his bedroom, but took her home when she said she didn’t want to do anything. Then, he occasionally made sexual comments to her afterward. To me, the only problem there is the alleged sexual comments afterward. Mostly, it sounds like Brown was guilty of being an awkward guy who made women feel uncomfortable.
But in this case, the accusations were enough for Brown to lose his position as the future Premier of Ontario (according to polls). There was no court, no hearing. Just a career instantly cut short.
So where’s the balance?
Maybe it’s unavoidable that people who chose jobs where they’re in the public eye can be brought down in hours by an unproved allegation. If I could arrange the world in any way I liked, I would still have no idea how to create a system that both allowed the concerns of women to be taken seriously without destroying the lives and careers of the accused based only on allegations. Even so, a swing toward “guilty because accused” doesn’t sit well with me.