
Artificial intelligence—and neural nets in particular—have been gaining attention lately. The most prominent example is the rise of self-driving cars, but the example that made me sit up and pay attention was the news that a neural net created by Google called AlphaGo had defeated one of the top go players. For me, this was a particularly noteworthy event.
Kasparov, the best human chess player of the 20th century, lost to a computer in 1997. That defeat surprised some, but I was studying computer science from 1990-1996, and it was generally accepted by most computer scientists at the time that within years computers would be better at humans at chess. So that defeat was relatively predictable.
But in the mid-1990s, the general consensus seemed to be that it would take a lot longer for a computer to master go—I remember wild guesses that it would take until 2050 or even 2100 before a computer challenged humans in that game. So, when AlphaGo won, it meant that something big had changed in the world.
And I wanted to find out what it was. In university, I did some of computational linguistics (teaching computers to understand human languages), but nothing related to neural nets. So, I decided to take Andrew Ng’s deep learning courses on Coursera to find out what I’d been missing. I found a couple things that surprised me.
How neural nets work
The first thing that surprised me (and this might indicate just how ignorant I was about the topic), was the realization that neural nets are just big math equations.
To train a neural network, you’re saying, “If I think a math equation has a particular form, what constants will make that math equation true most of the time.” Similarly, when you do predictions with the neural network, you’re just taking an input and running it through the math equation to see what the answer is.
So, the go-playing computer is essentially a big math equation that takes as input the location of each stone on the board, and spits out location where the next stone should be placed.
Why do I find this surprising?
The reason I found that surprising is because the process of training the network is basically nonlinear regression. “Nonlinear regression” sounds scary, but, if you take away the intimidating terminology, it’s a concept that most people understand intuitively.
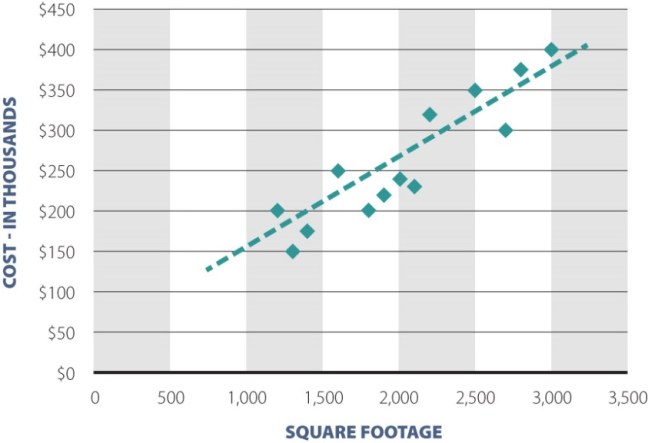
If you look at house prices, you’ll find that houses with more square footage generally have higher price. So take a bunch of houses, and for each house, put point on the chart, like the picture above. The more square footage, the farther to the right the point. The more expensive the house, the higher up the page. You’ll end up with a bunch of points that roughly form an angled line. If you draw a line through those points as in the picture, you’re doing linear regression.
Nonlinear regression is the same thing, but instead of drawing a line, you’re drawing a smooth curve approximating those points. (Nonlinear = not a line.)
Building a neural net is like staring at a bunch of points, deciding a particular type of smooth curve will go through most of those points, and then figuring out what the curve should be.
The challenging bit
Of course, when you’re telling a computer to draw the curve, it becomes a bit more complicated because you have to tell the computer exactly how to decide which curve is best. But even then, the concepts aren’t particularly complicated.
One common way to decide which curve is best is to find the curve that minimizes the distance between the curve and all the points-we want each point to be as close to the curve as possible.
But, if you have, say 10,000 points, calculating that exact curve can be hard. So hard that the people designing neural networks don’t even bother trying to solve the problem. Instead, they guess what a solution might be, see how badly their curve fits the points, and then make another guess until they get an answer that’s close enough to make people happy.
An example
For instance, suppose we decide a line will fit our points well, and we’re just trying to figure out the slope of that line. Furthermore, suppose that (though the neural net designer doesn’t know this), if you try different values for the slope, calculating the average distance of each of those points from the line, you find that the curve looks like a parabola (the blue parabola in the picture below). Essentially, if we guess the slope of the line is 2, we calculate that the average point is a distance of 4 away from the line. When we guess 1, the average point is a distance of 1 away.

Since we want to minimize the average distance of the points, we want to find the lowest point in the parabola. If you look at the picture, this place is clearly the zero position—that’s the lowest part of the blue curve.
But the neural net scientist doesn’t know that the relationship between slope and distance is a parabola, so they might randomly guess that the minimum point is at the 2 position on the axis. They’ll run the numbers, and see that the curve at that point is still sloping down, so the actual minimum must be to the left of 2.
So they need to guess again with a number that’s less than 2. To pick that new number, they’ll draw the red line showing the slope of the curve at position 2 and see that it intersects the horizontal axis at 1. So then they’ll guess that 1 is the answer.
But even at 1, the curve is sloping, so they’ll have to repeat the process, drawing the red line again, coming up with a new guess, this time coming up with 0.5. And they’ll keep repeating the process, walking ever closer to the actual minimum at zero, finally quitting when they decide they’re close enough.
Thus, they might eventually conclude that the slope of the line should be 0.0001 and in this way. they will have found the curve that (almost) minimizes the distance between the pints and the line.
Adding complexity
So, if this is all neural nets are—equations that are derived from minimizing the distance of a bunch of points from a curve—the obvious question is, “why did it take so long to get to where we are?” The answer is that, while my examples are in two dimensions, the neural net that actually work are solving equations in much higher number of dimensions. Instead of trying to find the bottom of the parabola, imagine trying to find the bottom of a bowl. Doing this changes the two dimensional parabola problem into a three dimensional bowl problem.
And neural nets don’t stop there, but usually have a much higher number of dimensions. I imagine most “real” neural networks today have at least a thousand dimensions they are trying to solve for, making the resulting equations far more complex. For instance, if you want to analyze a 640×480 photo (with three color dimensions) to decide if it contains a stop sign, you need an equation that has 921,600 inputs. Then, you have to find the thousands of parameters that take those inputs and spit out a simple “yes” or “no” when asked if there is a stop sign in the picture
So, these equations are really big and complex, and historically we didn’t have the processing power work out the equations in reasonable amounts of time. Neverthless, I find it remarkable that, despite this complexity, the core ideas used to create neural networks are rather intuitive. We take something simple and understandable and get something remarkable when we multiply it ten-thousandfold.
The second surprising thing
The other thing that surprised me about neural networks was related to the course itself. In Ng’s course, the majority of the citations were between 2010 and 2016. While neural networks were certainly a thing when I went to university in the early 1990s, the technology has progressed so rapidly in recent times that most of the citations in a “start from nothing and learn neural networks” online course are from the last 8 years. Forget the self-driving cars, the game-playing robots, and the media buzz. To me, those citations are indicative of just how much neural networks are exploding right now.

A good explanation of how neural networks achieve their goal. I recall from the early days (1980’s) discussion of electronically solving issues by ‘guessing’ and looking to see if the
answer seemed right.
LikeLike
Yeah, basically neural nets always start with a guess, and that’s part of how the instructor initially describes one way of creating a neural net. In the past, I’ve tried writing “random guessing” algorithms for various problems, but they tend to converge to the answer too slowly, so I almost always have to think. 😦
LikeLike